
The Perils of Insta-Research
Potential Impacts of AI (and Search Engines) on Information Literacy and Researching

Intro: How We Got to Now
I first read How We Got to Now before I went to my undergraduate program at Utah State. Steven Johnson’s seminal work on cultural and social evolution outlines how diverse innovations across time have culminated in our contemporary ways of life. Through a tapestry of seemingly unrelated breakthroughs in various fields, Johnson demonstrates how the world’s cultural and technological advancements have coalesced into the systems we now often take for granted. This approach is particularly illuminating when applied to the evolution of research methodologies and the ways we consume information.
First, people had root cellars that they dug deep in the ground. Then, people began to cover things with ice that was delivered by an “ice-man” (hence the popular play, “The Ice-Man Cometh.”). When freezer or “refrigerator” cars were developed, this eliminated the need for an ice-man except in the most rural communities. Ice boxes also reduced the frequency with which one would need to purchase ice. Then, freezers were invented, as well as the ability to make ice on one’s own home. The need for constant freezer electric power was further reduced when coolers and gel ice packs were invented.
With each new progress, the people who invested in and promoted the current solution as the “only way” lost money. People who were comfortable changing from the past solution to the new one were able to adapt quickly to a new solution to an old problem.
To be clear, ice itself didn’t go away (we still make ice today, even though we don’t necessarily need it to keep food fresh). Ice packs and coolers exists, but we still use freezers. There are four or five ways that we can keep food frozen and eatable, and we use them all in different ways, for specific contexts and purposes.
We can also use these methods to examine how artificial intelligence and search technologies influence information literacy and research practices. From the printing press to digital databases, and now to AI-driven search engines, each advancement has reshaped how we interact with knowledge. What once required meticulous study and careful sourcing can now be expedited with a single prompt or query. However, this shift is not without its trade-offs. By tracing the trajectory of how we arrived at this juncture, we can begin to understand the potential perils and promises these technologies hold for future researchers.
Before Search Engines: All Materials Have Bias
Research, in its pre-digital form, required a level of engagement that inherently acknowledged bias, even if indirectly. Scholars and everyday learners navigated libraries, encyclopedias, and journals, aware that every source carried the influence of its creators. Even then, biases ranged from the editorial (choices made by publishers) to the societal (what narratives were prioritized or marginalized). This inherent filtering shaped not only the content available but also the literacy required to interpret it.
When we moved to digitized collections, the biases did not disappear; they evolved. The sheer accessibility of digital materials often obscured the fact that even in this democratized format, creators, curators, and algorithms still mediated information. This shift to digital was pivotal in laying the groundwork for the mass adoption of search engines, but it also introduced new challenges, as the breadth of information available expanded faster than the tools needed to navigate it.
From Conspiracy Theories to Misunderstandings
The biases in materials, combined with the sheer volume of information available online, created fertile ground for the spread of both intentional and unintentional falsehoods. Misunderstandings and conspiracies often grew out of a mix of poor information literacy and misplaced trust in aesthetically convincing sources. The advent of the internet made it easier to distribute misinformation quickly and at scale, leading to a proliferation of malinformation, misinformation, and disinformation—each distinct in its origin and intent but equally problematic in its effects.
Misinformation is false, but not created or shared with the intention of causing harm.
Disinformation is deliberately created to mislead, harm, or manipulate a person, social group, organization, or country.
Malinformation is based on fact, but used out of context to mislead, harm, or manipulate.
The Pacific Northwest Tree Octopus: A Satirical Educational Resource
A deliberately satirical example like the Pacific Northwest Tree Octopus highlights the thin line between humor and deception in information literacy. Designed to educate students on evaluating online claims, this fictitious creature ironically passed the widely used CRAAP test, a 2004 framework. The problem? CRAAP primarily evaluates surface-level indicators of credibility, allowing convincing but false narratives to slip through. While this example was satirical, the same principles have allowed sincere false beliefs, like the supposed existence of the Magdeburg Unicorn, to persist historically and in modern contexts.
The Magdeburg Unicorn: A Case of Earnest Misbelief
The Magdeburg Unicorn is an exemplary case of a genuine misunderstanding that became part of cultural lore. Discovered in 1663, this supposed fossil reconstruction attempted to illustrate a mythical creature but was built from random animal bones. Yet, it was earnestly believed by many for centuries, fueled by the prestige of the authorities presenting it and the lack of a robust framework for assessing claims. This highlights how even earnest efforts at discovery can contribute to the dissemination of misinformation, particularly when they lack scrutiny.
The story of the “unicorn” becomes even more unreliable. The chain of reporting regarding its supposed nature was lost between its original discoverers and Otto von Guericke, who drew up the bones in their “reconstructed” skeleton form in a field book, which is now lost. The earliest depiction that we have access to is one created decades later by Gottfried Leibniz, a legitimate scientist, in one of his works, Protogaea.
The Magdeburg Unicorn story demonstrates how misunderstandings, and earnest attempts to understand and act on incomplete data, can cause errors that last for decades and even centuries.

From CRAAP to SIFT: A Shift in Focus
The CRAAP test, widely used in educational contexts, offered a structured way to evaluate information but also revealed significant flaws. Its focus on aesthetics and surface-level attributes often fell short in distinguishing fact from fabrication. The reliance on traits like "authority" and "currency" became problematic in an age where false information could appear polished and up-to-date.
In response, the 2010s saw the emergence of the SIFT method, a framework designed to address these shortcomings. By emphasizing steps like Stop, Investigate the source, Find better coverage, and Trace claims to original context, SIFT encouraged users to look beyond appearances and evaluate information critically. Unlike CRAAP, which focused on the presentation of data, SIFT prioritized understanding the origins and veracity of claims.

Before AI: Search Engines Were Already Bad
Long before the advent of generative AI, search engines shaped the way individuals accessed and interpreted information. While they revolutionized accessibility, they also introduced systemic flaws that have only deepened with time. Search engines rely on algorithms to rank and present results, yet these algorithms, despite their perceived neutrality, are designed and trained by humans, meaning they inherit human biases and limitations.
Situating Search: Bias in Algorithms
The work of Bender and Shah (2022) situates search within the broader context of algorithmic design and societal structures. Their research emphasizes that search engines are not merely tools for information retrieval but also systems that mediate access to knowledge. This mediation often skews results, privileging certain narratives, voices, or commercial interests over others. Algorithms, they argue, are not neutral arbiters but active participants in shaping public discourse.
Bender and Shah also consider the idea that the purposes, nature, resources, and strategies used by researchers have changed since “search” became an academic activity. In the 1980s, humans used databases. The next decade or so brought databases together and supplemented them with websites, forums, and networks. Search engines helped users navigate all of these as an apparent whole. In the present day, “search” is facilitated by a multitude of sites, including search engines. But even these have changed from their previous state (we’ll talk about that more below).
Bender and Shah also note that, as researchers recognized as early as the 1990s, there are at least 16 “information seeking strategies” and 20 “search intentions,” and the current versions of search engines are not fulfilling many of them. Developers are concerned about providing what they can do instead of fulfilling what their users need.
Algorithms of Oppression
Commercial interests are not the only influence on the bias of algorithms. Safiya Umoja Noble’s Algorithms of Oppression further illuminates how search engines, through algorithmic biases, perpetuate systemic inequalities. Noble’s investigation reveals how marginalized groups are frequently misrepresented or altogether erased in search results, a reflection of the data sets and priorities used to train the algorithms. For instance, searches for terms associated with Black women often yield harmful stereotypes, exposing how the very systems we trust for information perpetuate inequities.
This phenomenon is compounded by the prioritization of profit-driven metrics. Search engines optimize for engagement, not accuracy or fairness, often amplifying content designed to provoke emotional reactions rather than inform. This has led to the proliferation of clickbait and sensationalism, creating a digital environment where misinformation and disinformation thrive.
Controlling the Narrative with SEO
Things would be bad enough with search engine inadequacy and algorithm biases, but there are also those who deliberately skew the results. Search engine optimization (SEO) practices further exacerbate these issues. SEO involves deliberately including keywords and related phrases in the text of a website to skew a page’s position in a search engine results list. There are ethical ways to do this, but a large number of SEO operations are unethical and in bad faith.
Organizations and individuals adept at leveraging SEO techniques can manipulate rankings to control narratives, often prioritizing commercial interests or political agendas over truth. By exploiting algorithms, they ensure their content appears prominently, regardless of its reliability. This manipulation of visibility not only distorts public understanding but also reinforces the dominance of those with resources to engage in such practices.

Advent of AI: “AI Knows Everything”
Ever since ChatGPT was released to the public in November 2022, the erroneous idea has spread that “AI knows everything.” Partly, this belief was connected to the other falsehood, that “AI was trained on the entire internet.” In reality, it was trained on Wikipedia, Project Gutenberg, and open-source datasets like WebText and CommonCrawl. It was trained on one one-hundred-billionth of the internet. This means that it is neither comprehensive or all-knowing.

For some reason, despite its non-thorough nature, we are prone to automatically believe everything AI says. If we ask a question, we expect good faith answers. However, the problem is that since the AI tools we communicate with are not human, they have no ability to have good faith.
AI will confidently tell us answers that are completely wrong. Case in point: a year ago (almost exactly), you could ask ChatGPT and Gemini “what is the world record for crossing the English Channel on foot” (which is impossible)? Both tools would give you a confident answer of the person who had the record, what that record was, and a story about the athlete’s background. When you reprimanded the tool and told them that crossing the English Channel on foot was impossible, it would apologize and say “yes, that is completely untrue. I made it up because I thought that was what you wanted me to say.”
In a way, these AI tools were operating like the Google algorithm that changes its responses to your keyword query based on the order of the keywords, the emphasis you give them, and your previous search history. They were (and are) not concerned with giving you data-consistent answers. They are concerned with giving you the answers that will satisfy you.
I have compared this to the story “Liar!” by Asimov multiple times, so I will spare you the detailed description here. It reminds me of this quote by Lowell Mather, the mechanic on Wings:
“The loss of physical prowess as we age should not be a source of shame, something to be hidden from the pity of a younger, more capable world. As Dylan once said, ‘Do not go gentle into that good night. Rage! Rage! For the times, they are a’changin’.”
Web-Enhanced AI: “Enhanced,” Not “Completely Reliable”
I hope that the previous section has convinced you that AI is fallible, particularly when you ask it definitive questions. Somehow, search engine providers have thought it beneficial to combine search engines, with their plethora of problems, and AI natural language processing. The result is even worse than either of them by themselves.
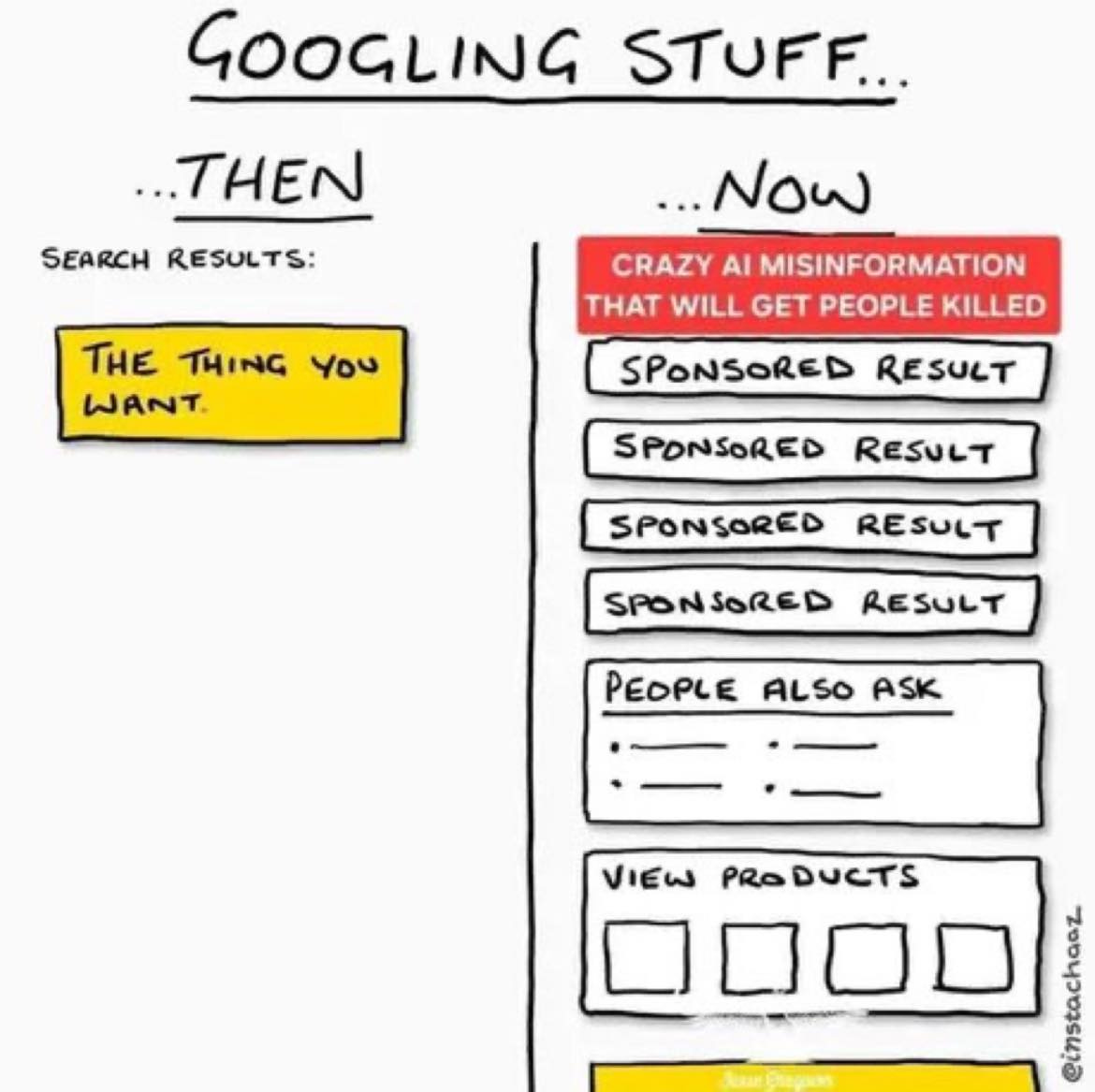
Why wouldn’t AI tools, with their built-in data analysis, cancel out the negative inclusion of ads and SEO-boosted content that have become so prevalent in modern search engines? The answer is that the RAG and LLM processes that make AI fallible are still in the new tool. In fact, the AI Overview of Google mostly uses text generation to come up with its response. Then, it finds sources to back up its claims. (ChatGPT Search, on the other hand, does the opposite).
In other words, rather than ameliorating the problems of the search engine through the processes of AI, the issues of both tools are exacerbated.
Like I said in Understanding and Using ChatGPT Search, I personally have ChatGPT Search as my “default search” tool. This is not because I think it is more useful than Google in terms of the act of searching. However, I do think that it is more reliable in terms of the links it finds. With Google and Bing, you have to sift through:
text-generated (non-RAG) answers that are often not reliable,
sponsored ads masquerading as search results,
SEO-optimized (hackneyed) results,
and then reliable links to high-quality sources.
When you query ChatGPT Search or Perplexity, you have to parse through information you get from the output, but at least you can look at the links. You do not have to worry if they are included in an output because they were paid for by sponsors. Search Engine Optimization may bias the output slightly, but enough of the legitimate sources should be present to show the consensus of authoritative sources (that may be wishful thinking), especially for users who exercise information literacy skills.

Conclusion: Become Uncomfortable with Instantaneous Gratification
This is a combination of my dad’s and wife’s sayings and a quote by young adult author Lloyd Alexander. My dad always says that people should “get used to being uncomfortable,” or else they aren’t doing worthwhile things with their life. My wife counsels clients and others who have difficult experiences to “fully immerse yourself in the jarring-ness.” In other words, solutions are not going to come easily when you have issues, and you should embrace that rather than fight against it. As Dallben in The Book of Three says, “ in some cases, we learn more by looking for the answer to a question and not finding it than we do from learning the answer itself.”

When we commit to using thorough information literacy skills, we learn to be distrustful of answers that come more quickly than we are expecting. This includes answers in sponsored ads, but also includes the “AI Overviews” and the first replies from generative AI tools. We should use the SIFT method, as well as plain common sense, to ensure that the sources we believe, in any format, are the most accurate. Insta-research can only lead to insta-errors, insta-bias, insta-trouble, and, ultimately, insta-regret.
"In fact, the AI Overview of Google mostly uses text generation to come up with its response. Then, it finds sources to back up its claims. (ChatGPT Search, on the other hand, does the opposite)."
Probably not important but that's a interesting nugget on how Ai overview works. Do you have a cite or link?
I've often wondered why Google Ai overviews seems far worse than normal RAG search systems.
From the technical point of view i think it does not matter if it generates first, looks for things to back it up and edit the text if it does not etc as RAG variants include "generate and search" as well as the more common "search and generate" style and both if properly implemented should be equalvant.
My guess is Google ai overviews is bad more because it's designed to be fast and light weight due to costs (number of Google users are insane)