
AI in Preexisting Web Services
How AI Has Impacted Social Media Since the 2010s (possibly Insta-Research Pt. 2)

In November 2022, when ChatGPT was released, the whole world acted like the field of artificial intelligence had never existed until that moment—we all hovered around our computers and asked LLMs all types of questions—and feared that the entire field of writing was going to be changed forever.
Okay, that was a bit hyperbolic, but not much. ChatGPT raised some serious questions about the interactions between human and machine. However (and I am going to be in a panel related to this topic at 2025 AECT International Convention), similar issues with AI in general (and algorithms specifically) have been had ever since Google started using algorithms and Facebook tracked user data.
When Facebook started using Meta AI, it seemed like everyone was concerned about tracking and using user data to manipulate their experience on the site, but that had already been happening for at least ten years before (we’ll go into that below).
This post is going to explore how AI has and is being incorporated into preexisting services and sites beyond the chatbots that pop up in the corners. It may surprise you to learn that AI was a part of these services years ago, but it was not referred to as AI until people were paying attention to that technology.
Then (full disclosure), I will tell you about a resource that I have created to help with research in the age of AI.
For my high-level “history of search” or “history of info-lit,” read this article:

AI and Google
Gmail Algorithm: Google Magic to Separated Inboxes
“Important according to Google Magic.” This phrase (and other variations, including “magic sauce,”) first appeared in 2010, and users were very happy about it (at least in my circle, although we were high schoolers and young college students). Messages with urgent-sounding keywords and between ourselves and repeat correspondents were given special labels or bolded or italicized in a way that brought our attention. For the time being, we had a way to separate the “important” emails from spam messages.
In 2013, a massive change occurred that went beyond “Google Magic.” Inboxes were sorted into “Primary, “ “Promotional,” “Social,” and “Updates,” and each section had a different color. Essentially, the criteria for sending a message to the Primary inbox is:
The user initiates the conversation, or
The message is sent from someone with whom the user has previously had a conversation, or
The message is sent from an address that has a certain type of domain or use case (for example, a meeting scheduler or an .edu website) with whose messages the user has previously frequently interacted.
This system is far from perfect (some of the Spam emails I get are actually things I want to receive, and some of the Promotional emails are actually receipts), but by and large my Primary inbox has been the main receptacle for my important correspondence

AI-Enhanced Cards and Overviews
While the AI Overviews in Google’s searching experience have only been around a few years, Google itself has, obviously, existed for just over two decades. In between Google’s inception and the incorporation of AI Overviews, Google introduced the idea of person-, organization-, or topic-related “cards” (or “Knowledge Panels”) that appeared at the top of certain searches.
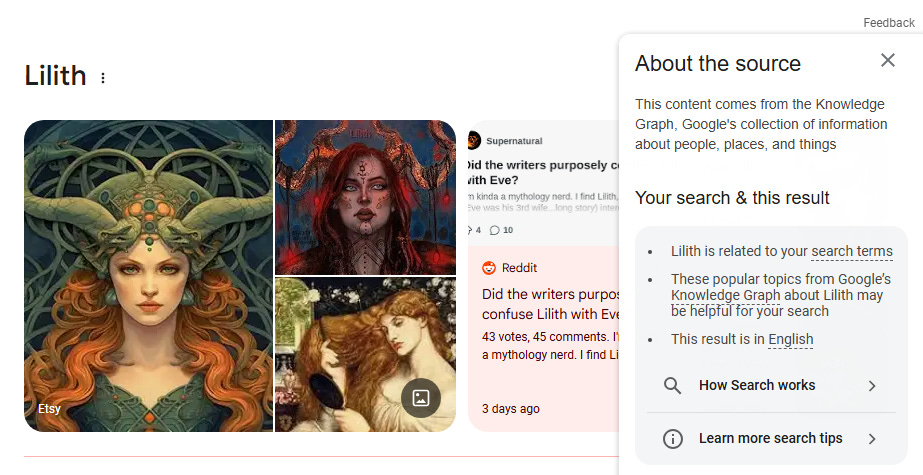
These cards are selected from Google’s “Knowledge Graph,” which is a “collection of information about people, places and things.” When you searched for a particular topic from 2012 until 2014, the first thing that appeared was a standardized card, which could include images, text, links, and other resources that the general public had found useful when they had searched that topic.
From 2014 until the present day, Knowledge Graph cards were occasionally accompanied by snippets from one or two search results. These were never combined together but instead offered in sequences as potential sources of information. Unless the site was a general sources of information, like Wikipedia, sites from which such “featured snippets” were selected were determined based on keyword density (potential to help the current user) and if a particular site had been helpful to a previous user who had searched a similar query

Just over one year ago, Google began using “AI Overviews” in its search results. This adaptation of both Knowledge Graph and “featured snippets” sought to essentially combine snippets together to give a more nuanced perspective, while also communicating using natural language processing to prompt a more conversational research experience.

.
Within one day, it was telling people to put glue on pizza and eat certain rocks to increase the minerals in their blood.
AI and Facebook
Facebook Algorithms
Since at least 2010, Facebook tracked users and analyzed their actions based on predetermined demographic categories. Initially, this was used to promote certain pages to users, but before long there were third-party advertisements that were calibrated toward people with certain demographic and ideologic backgrounds.
If one was paying attention to the Terms and Services, and noting the ads that one viewed, the connection between data tracking and the ads was somewhat apparent. 2010 was the year that, to my recollection, “the phones started listening” to user conversations.
In reality, Facebook connected data regarding use of its app and post content with the data from other apps, such as Google apps and/or shopping sites. This gave all purveyors a more accurate profile with which to persuade you through calibrated suggestions.
Facebook did not stop there, however. It persuaded site creators and blog writers to put “Facebook like” buttons on other websites. In return, Facebook would notify a user’s connections that a particular page, item, or post was “liked,” thus increasing traffic to that external page. This “Like button” gave Facebook the ability to track users even when it was not using the site proper. This tracking occurred even when users did not interact with the Like button.
Although hindsight is 20/20, I would like to think that we all knew that putting code from another services into one’s own site would give that site some form of access to use data or something else. The point is, data was tracked, amalgamated, categorized, and used to create the most attractive Facebook experience ever.
In 2014, Facebook finally owned up to what it was doing. “We’ve been calibrating your ads for years, and now you can see what categories we have put you into!” Many users were furious, but some younger ones (like myself) were merely intrigued—how could a site get so many demographic categories right, and others so wrong?
The answer, of course, was AI. Facebook was using predictive artificial intelligence, what we refer to as “algorithms,” automate advertisement visibility or page follow suggestions. Facebook only went public with this detail in 2018, so it is likely (if other things they were belatedly transparent about are any indicator) that they were using it much earlier). I wish I would have saved a screenshot of all of the data they had on me in 2014, because it was truly intriguing to see how many aspects of a user’s life (from politics to favorite foods to favorite exercise sport, to religion) Facebook was tracking. There was a even a brief “explanation” as to why a user was assigned to particular category (Mormons, such as myself, were all assumed to like basketball, be interested in Utah politics no matter where we lived, and be Republican, though none of those generalizations are true).
About every five years, people remember this and have a massive problem with it, as though “this is the first we have heard about it.” It seems that we prefer to persistently forget about data tracking. I only say this because when Facebook released Ad Preferences, it was a persistent notification on my profile for at least a month.
We have already looked at how Facebook advertisements were calibrated on the micro scale. On the macro level, Facebook looked at the possibility of an ad having higher than a certain percentage of success in a certain demographic group. It also used AI to determine if a certain user of a particular brand’s item would be susceptible to advertisement’s from a competitor brand.
Internally, the same predictive technology was used to suggest Facebook groups and pages with which users could join and interact. Predictive AI also determines the “most relevant” comments on a post. It can also help users see the most popular posts in one of their groups. Hopefully, I do not have to spell out how much this exacerbates biases, particularly confirmation bias, even regarding the most mundane topics (sourdough starter tips, or the best Frasier episode, for instance). The impact of this predictive machine is inescapable.
Much of this can now be seen (at least on a high level) on the Meta Transparency Center or Facebook Help Center.
Facebook now admits to tracking the following data points and using them to calibrate group and advertisement requests:
Geographic information, like the current city listed in the About section of your Facebook profile, to suggest groups with members nearby.
Demographic information, like language and age, to suggest groups with similar members
Groups someone you’re friends with has already joined or participated in and Pages they’ve followed
Your activity in a group or Page, like if you’ve posted or interacted with posts about cars
Your recent activity on other Facebook features like Marketplace, Search, Video and Events, like items you’ve sold, videos you’ve watched and events you’ve attended
Trending or popular topics in groups
Information you’ve added to your profile, like your interests

The above picture is the toned-down version of the transparency that Facebook provided in Ad Preferences before it became more opaque. This is a subset of my user data.
All of this is to say, artificial intelligence in some form has been present in Facebook for more than a decade. The massive amount of data collected on each Facebook user primed Facebook (or, more accurately now, “Meta,”) to incorporate more AI tools—this time, generative rather than predictive.
Meta AI
Meta AI is not a ranking system or a predictive ad system. Instead, it is an LLM chatbot, like ChatGPT, that converses with a user about a post. It also goes into group comments (and some non-group posts if they are active enough) and summarizes (with about 75 percent accuracy and no proclivity toward subtext) the essence of the comments. The end result is that users can interact with, and converse about, posts and advertisements without actually talking to a human. In a way, Meta AI removes the “social” from “social media.”
YouTube Algorithms
Before YouTube was associated with Google, they were already incorporating algorithms to determine which videos would be most-likely played next by a user or group of users. This is why I have listed them separately from Google.
The initial YouTube algorithm, as no one had any idea about clickbait, only focused on which videos had the most views, which were activated by clicking on the video thumbnail (which gave rise to “clickbait,” incidentally.”) In 2012, after seven years of a mismatched algorithm, the developers switched to an algorithm that focused on the length of time that videos were watched, particularly in relation to the total time length of the video.
From 2016, the algorithm also incorporated past view data of the individual user, as well as past YouTube (and, when Google acquired YouTube, Google) searches and channel subscriptions to give them viewing options based on their metadata and proclivities.
If you are as dull as I am, you might find this video regarding the history of the YouTube algorithm as interesting as I did:
Also, if you prefer a text version, Matt Southern consolidated six YouTube “Creator Insider” videos regarding the algorithm into a brief article. His summaries are accurate representations of the videos, but you can watch them for yourself from the links in his references section.
A Webinar to Help with AI-Enhanced Research
As I have talked about in some of my past presentations (but have not written about yet,) if companies have been collecting, selling, and using our data for decades now, AI tools are not really that much more dangerous. This does not mean that we should not protect data privacy. Rather, it means that we should apply the same data privacy strategies that we apply to other services.
In a similar way, social media and web browsing and searching services have been using algorithms and metadata to calibrate our web experiences for years, and so we should be open to using LLMs and other technologies for research just as we have search engines. I talk about that a bit in the “Insta-Research” post.
In my last post, I referenced a webinar that I created alongside Steve Hargadon of Library 2.0. “Research and AI” explores the transformative potential of AI in academic research and digital information literacy.
This webinar is the video, discussion version (and expansion) of my “Insta-Research” and other AI-and-research articles. In this discussion, focus on using text generators for research, but we also look at several applications of AI in research tools and examine their benefits and drawbacks.

By the end of this session, you will be able to:
Understand the functions and limitations of AI tools like ChatGPT, Semantic Scholar, and Perplexity in academic research
Develop critical thinking skills tailored to assessing AI-generated information, including identifying bias and evaluating accuracy
Gain practical techniques for integrating AI responsibly into the research workflow.
This session is available for the per-person cost of $129 and also comes with a video overview of Google Deep Research. Group rates are $99 each for 3-4 registrations, $75 each for 5 or more registrations. Large-scale institutional access (each individual can view the video on their own) is $599. Contact admin@library20.com or go to the link above to purchase the recording.
Would you like this post to become a webinar? Email me at reed.hepler@gmail.com or message me on my LinkedIn profile. Steve and I are always looking for more ideas for webinars and bootcamps!